Grid, Cloud, HPC ... What's the Diff?
It’s always nice when another piece of the puzzle comes into focus. In this case, my time speaking at the first ever International Super Computer (ISC) Cloud Conference the week before last was well spent. The conference was heavily attended by those out of the grid computing space and I learned a lot about both cloud and grid. In particular, I think I finally understand what causes some to view grid as a pre-cursor to cloud while others view it as a different beast only tangentially related.
This really comes down to a particular TLA in use to describe grid: High Performance Computing or HPC. HPC and grid are commonly used interchangeably. Cloud is not HPC, although now it can certainly support some HPC workloads, née Amazon’s EC2 HPC offering. No, cloud is something a little bit different: High Scalability Computing or simply HSC here.
Let me explain in some depth …
Scalability vs. Performance
First it’s critical for readers to understand the fundamental difference between scalability and performance. While the two are frequently conflated, they are quite different. Performance is the capability of particular component to provide a certain amount of capacity, throughput, or ‘yield’. Scalability, in contrast, is about the ability of a system to expand to meet demand. This is quite frequently measured by looking at the aggregate performance of the individual components of a particular system and how they function over time.
Put more simply, performance measures the capability of a single part of a large system while scalability measures the ability of a large system to grow to meet growing demand. Scalable systems may have individual parts that are relatively low performing. I have heard that the Amazon.com retail website’s web servers went from 300 transactions per second (TPS) to a mere 3 TPS each after moving to a more scalable architecture. The upside is that while every web server might have lower individual performance, the overall system became significantly more scalable and new web servers could be added ad infinitum.
High performing systems on the other hand focus on eking out every ounce of resource from a particular component, rather than focusing on the big picture. One might have high performance systems in a very scalable system or not.
For most purposes, scalability and performance are orthogonal, but many either equate them or believe that one breeds the other.
Grid & High Performance Computing
The origins of HPC/Grid exist within the academic community where needs arose to crunch large data sets very early on. Think satellite data, genomics, nuclear physics, etc. Grid, effectively, has been around since the beginning of the enterprise computing era, when it became easier for academic research institutions to move away from large mainframe-style supercomputers (e.g. Cray, Sequent) towards a more scale-out model using lots of relatively inexpensive x86 hardware in large clusters. The emphasis here on relatively.
Most x86 clusters today are built out for very high performance and scalability, but with a particular focus on performance of individual components (servers) and the interconnect network for reasons that I will explain below. The price/performance of the overall system is not as important as aggregate throughput of the entire system. Most academic institutions build out a grid to the full budget they have attempting to eke out every ounce of performance in each component.
This is not the way that cloud pioneers such as Amazon.com and Google built their infrastructures.
Cloud & High Scalability Computing
Cloud, or HSC, by contrast, focuses on hitting the price/performance sweet spot, using truly commodity components and buying lots more of them. This means building very large and scalable systems.
I was surprised at the ISC Cloud Conference when I heard one participant bragging about their cluster with 320,000 ‘cores’. Amazon EC2 (sans the new HPC offering) is at roughly 500,000 cores, quite possibly more. And Google is probably in the order of 10 million+ cores. Clouds built around High Scalability Computing are an order of magnitude larger than most grid clusters and designed to handle generic workloads, requiring hitting the price/performance sweet spot when building them.
Grid workloads can be very, very different.
Some Grid Workloads Drive the Grid Community
In talking to the grid community I learned that there are effectively two key types of problem that are solved on large scale computing clusters: MPI (Message Passing Interface) and ‘embarrassingly parallel’ problems. I’m using terms I heard at the conference, but will use MPI and EPP (embarrassingly parallel problem) so that I can shorthand throughout the rest of this article.
MPI is essentially a programming paradigm that allows for taking extremely large sets of data and crunching the information in parallel WHILE sharing the data between compute nodes. Some times this is also referred to as ‘clustering’, although that term is frequently overloaded today. Certain kinds of problems necessitate this sharing as the computed results on one node may effect the computed results on another node in the grid. MPI-based grids, the de facto standard for most academic institutions, are built to maximum throughput and performance per system, including the lowest latency possible. Most of them use Infiniband technology for example to effectively turn the entire grid into a single ‘supercomputer’. In fact, most of these MPI-based grids are ranked into the Supercomputer Top500.
An MPI grid/cluster, in many ways, looks more like an old school mainframe and technology such as Infiniband essentially turns the network into a high-speed bus, just like a PCI bus inside a typical x86 server.
EPP workloads, by contrast, have no data sharing requirements. A very large dataset is chopped into pieces, distributed to a large pool of workers, and then the data is brought back and reassembled. Does this sound familiar? It should, it’s very similar to Google’s MapReduce functionality and the open source tool, Hadoop. EPP workloads are very commonly run on top of MPI clusters, although some academic institutions build out separate or smaller grids to run them instead.
The majority of grid workloads are of the EPP type. The diagram below shows this.
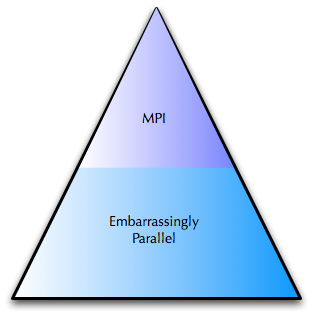
I had one person confide in me that “MPI power users drive grid requirements for vendors and assume that if their problems are solved, then the problems of [EPP] users are solved.” This is interesting since these two types of workloads have different needs.
HPC vs. HSC
The reality is that High Scalability Computing is ideal for the majority of EPP grid workloads. In fact, large amounts of this kind of work, in the form of MapReduce jobs have been running on Amazon EC2 since its beginning and have driven much of its growth.
HPC is a different beast altogether as many of the MPI workloads require very low latency and servers with individually high performance. It turns out however, that all MPI workloads are not the same. The lower bottom of the top part of that pyramid is filled with MPI workloads that require a great network, but not an Infiniband network:
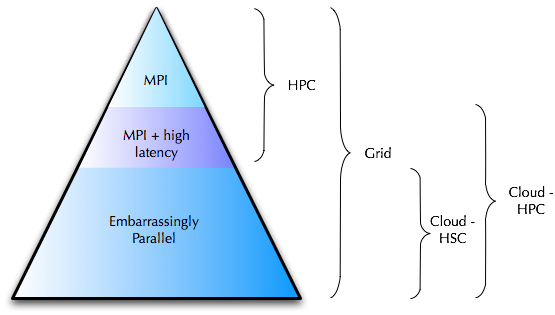
In keeping with Amazon Web Service’s tendency to build out using commodity (cloud) techniques, their new HPC offering does not use Infiniband, but instead opts for 10Gig Ethernet. This makes the network great, but not awesome and allows them to create a cloud service tailored for many HPC jobs. In fact, this recent benchmark posting by CycleComputing shows that AWS’ Cloud HPC system has impressive performance particularly for many MPI workloads.
HSC designed to accommodate HPC!
Which brings us back.
The Moral of the Story
So, what we have learned is that scalable computing is different from computing optimized for performance. That cloud can accommodate grid and HPC workloads, but is not itself necessarily a grid in the traditional sense. More importantly, an extremely overlooked segment of grid (EPP) has pressing needs that can be accommodated by run-of-the-mill clouds such as EC2. In addition to supporting EPP workloads that run on the ‘regular’ cloud some clouds may also build out an area designed specifically for ‘HPC’ workloads.
In other words, grid is not cloud, but there are some relationships and there is obviously a huge opportunity for cloud providers to accommodate this market segment. At least, Amazon is spending 10s of Millions of dollars to do so, so why not you?